Day 2 - Git's Data Model¶
Data Model¶
The data model of Git might not be the most essential in getting git to work but understanding what happens under the hood will allow you to have a greater understanding.
Git has 3 main data types:
-
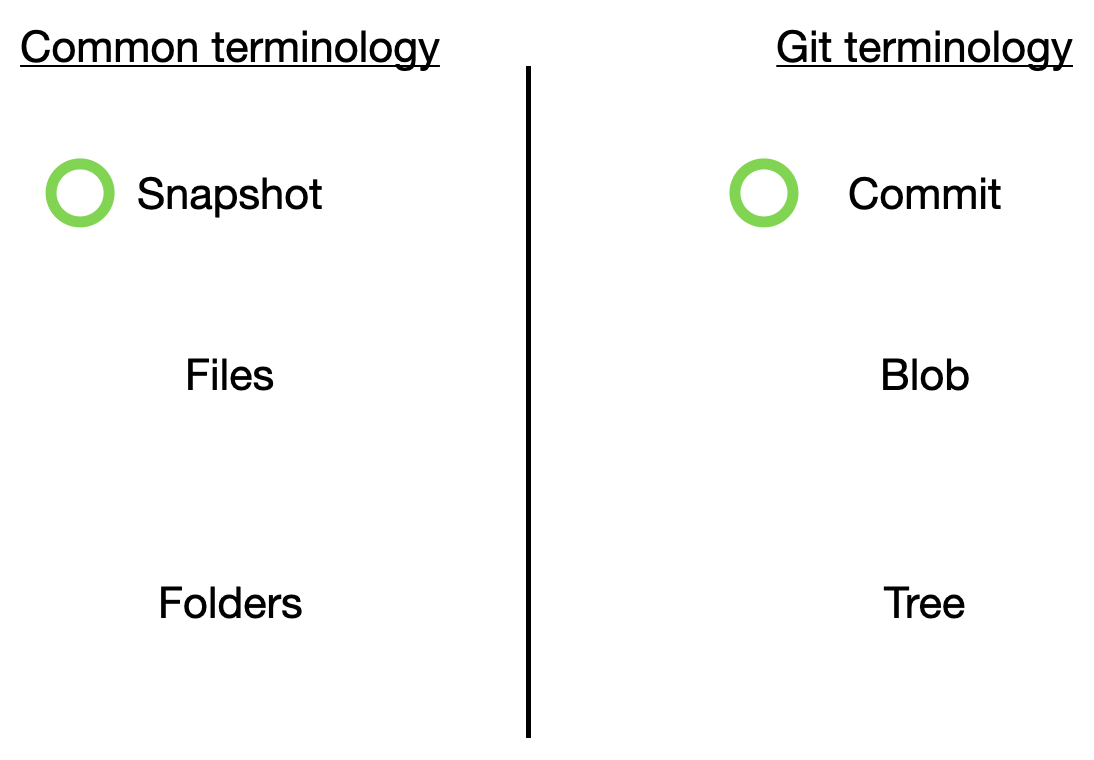
Blob Git terminology for Files
-
Tree Git terminology for Folders
-
Commits Git terminology for Snapshots
For each Commit, Git needs to store data on the current state of the file and more.
Each commit has the following data:
-
id A 40 char long String that is used to identify the commit.
Eg. "cf23df2207d99a74fbe169e3eba035e633b65d94"
-
Author Developer name that created the commit
-
Parent id of the preceeding / parent commit
-
Commit Message Meaningful message that the developer wrote to describe the commit
-
Snapshot The id of the tree / folder which contains files / blobs.
Key takeaways
Every commit has information regarding the state of files when the commit was created. It also knows which commit preceeds it, has a message to describe the purpose of the commit and has a unique identifier (40 character long string) like "cf23df2207d99a74fbe169e3eba035e633b65d94" to identify it.
Side note
With each commit being able to be identified by their id. This makes identifying them difficult as the 40 long char strings are meaningless and not useful to humans. Therefore, git uses branch names which will map a human readable String to the commit's id.
A commit / snapshot can have a branch name that can be mapped to locate which commit the branch name refers to. This gives a commit a meaningful name instead of "cf23df2207d99a74fbe169e3eba035e633b65d94"
Branch names and branching will be covered later on but this should give you a glimpse as to why we need branch names.
Example as follows: